CS346 Advanced Databases
Lecture 1 – October 5th, 2017
Significant part of the module: the back-end of databases. Other part: recent development in db tech.
In other words: 60% is data structures, 40% is operating systems.
For db performance, we care about I/O ops since db’s are usually stored on disk and not in memory. We optimise algorithms to minimise I/O ops involved. Clock cycles, or CPU comparisons are relatively cheap by comparison.
CS258 Recap…
CS258 was application design: start with a companies needs, construct E/R
diagrams, which later become tables in a relational database.
The relational model was invented by Cod at IBM. SQL became the standard for querying relational models.
This modules…
The back-end. How do you provide for the application guys from CS258?
Things that we discuss include:
- B-trees (n-ary balanced trees)
- multiple indices: querying multiple attributes simultaneously
- external hashing: hash points to different blocks on disk
- order of joins: what do you join first?
- OLAP: Can I change this relational model to make it more fit for analysis?
- Teradata: data warehousing company.
Lecture 2 – October 6th, 2017
Why use RDBMS
-
Controlling redundancy
Redundancy causes inconsistencies in the data, update costs, and storage overheads. Recent technologies aim to make data consistent, however the updates must be available eventually. -
Concurrency Control
DBs control concurrency themselves (not relying on the OS) to make sure the data can be accessed concurrently. -
Backup and Recovery
In case of errors, roll back to the last consistent state. -
Views, Access Control
Different people can see different parts of the database. -
Standardization (SQL)
Use the same language for querying irrespective of the underlying database technology.
When not to use a RDBMS?
Small dataset, model doesn’t change often, simple application.
Relational databases
-
Relational model
- Relational Data Structures
- Integrity Rules
-
Query languages
- Relational Algebra (useful for running queries efficiently)
- Relational Calculus
- SQL
Keys
-
A relation is a set of tuples. All elements of a set are distinct.
-
Hence all tuples must be distinct.
-
There may also be a subset of the attributes with the property that values must be distinct.
Such a set is called a superkey.- a set of attributes
- and tuples
-
A candidate key is a minimal super key.
- A set of attributes, is a superkey,
- but no proper subset is a superkey.
-
A primary key is one arbitrarily chosen candidate key.
Integrity Rules
-
Domain contrainsts A data type for each item.
-
Entity integrity: Every relation has a valid primary key.
-
Referential integrity: if one column is a foreign key to another table, if a row has a non-null value as the column, it MUST exist in the foreign table.
Normalize
(…show tables from slides)
Storage, Files, and Indexing
Outline
Part 1
-
Disk properties and file storage
-
File organizations: ordered, unordered, and hashed
-
STorage: RAID and storage are networks
-
Chapter: “Dist Storage, Basic File Structures and Hashing”
Why?
Locality: similar objects in the same block Parallelism: if there are too many objects to fit in one block, spread them over many servers, clustered in the same block within each server.
Bottom-up perspective on data management.
Data on Disks
-
Databases ultimately rely on non-volatile disk storage
- Data typically does not fit in (volatile) memory
-
Physical properties of disks affect performance of the DBMS
- Need to understand some basics of disks
-
A few exceptions to disk-based databases:
- Some real-time applications use “in-memory databases”
Rotating Disk
-
Seeking means waiting for your sector of data to come round to the reading arm. Once you get there you want to do sequential I/O, not random I/O.
-
Too tidy sequential I/O: more data comes along and everything has to be shifted forwards.
-
When writing your DB application, you fit your block size to be reasonable. Say, 16MB.
-
Seek time: move read head into position, currently
- Includes rotational delay: wait for sector to come under read head.
- Random access: . Quite slow…
-
Track-to-track move, currently : 10 times faster.
- Sustained read/write time: (caching can improve this further)
-
Buffering can help multithreaded systems.
- Work on other processes while waiting for I/O data to arrive.
- For writing on disk, fill a buffer first. When the buffer is full, then write to disk.
- Double buffering: fill one buffer whilst another is being written to disk.
Records: the basic unit of the database
-
DBs fundamentally composed of records
- Each record describes an object with a number of fields
-
Fields have a type (int, float, string, time, compound…)
- Fixed or variable length
-
Need to know when one field ends and the next begins
- Field length codes
- Field separators (special characters)
-
Leads to variable length records
- How to effectively search through data with variable length records?
Lecture 3 – October 9th, 2017
Records and Blocks
- Records get stored on disks organized into blocks
-
Small records: pack an integer number into each block
- Leaves some space left over in blocks
- Blocking Factor: (average) number of records per block
-
Large records: may not be effective to leave slack
- Records may span across multiple blocks (spanned organization)
- May use a pointer at end of block to point to next block
File Organization
-
File: Sequence of records
- Fixed-length vs. variable-length records
-
Records are stored to disk blocks
- Spanned vs. unspanned
-
Blocks are allocated to disk
- Contiguous vs. Linked allocation
-
File Organization
- Unordered
- Ordered
- Hashing
Unordered Files
- Just dump the records on disk in no particular order
- Insert is very efficent: just add to last block
-
Scan is very inefficient: need to do a linear search.
- Approx. read half the file on average
- Delete could be inefficient
Ordered Files
- Keep records ordered on some (key) value
Hashing Files
-
Use hashing to ensure records with same key are grouped together
-
Arrange file blocks into M equal sized buckets
- Often, 1 block = 1 bucket
-
Usual hash table concerns emerge
- How to deal with collisions?
- Deletions also get messy
-
External hashing: don’t store records directly in buckets, store pointers to records.
- Pointers are small, fit more in a block
- “All problems in computer science can be solved by another level of indirection” – David Wheeler
External Hashing for Disk Files
- Bucket: One disk block or cluster of contiguous blocks (like fixed-size chaining)
- Hashing maps a key to a bucket number (which is then mapped to a physical block)
Dynamic Hashing
- Static hashing: hash address space is fixed.
- Dynamic hashing: Expand and shrink the hash space.
Extendible Hashing
For a table of size 2: use most significant bit for hash.
TODO: This is complicated. Write out a full description for this later.
Lecture 4 – October 12th, 2017
Points to Note
-
Does the order of insertion matter?
Not in this case. But in most cases we are inserting multiple rows at a time anyway. This is called bulk loading, where you find a way to efficiently insert reams of data instead of inserting tuples one by one. -
Bucket split causes directory doubling
- If local depth becomes > global depth
Linear Hashing: Example
Indexing
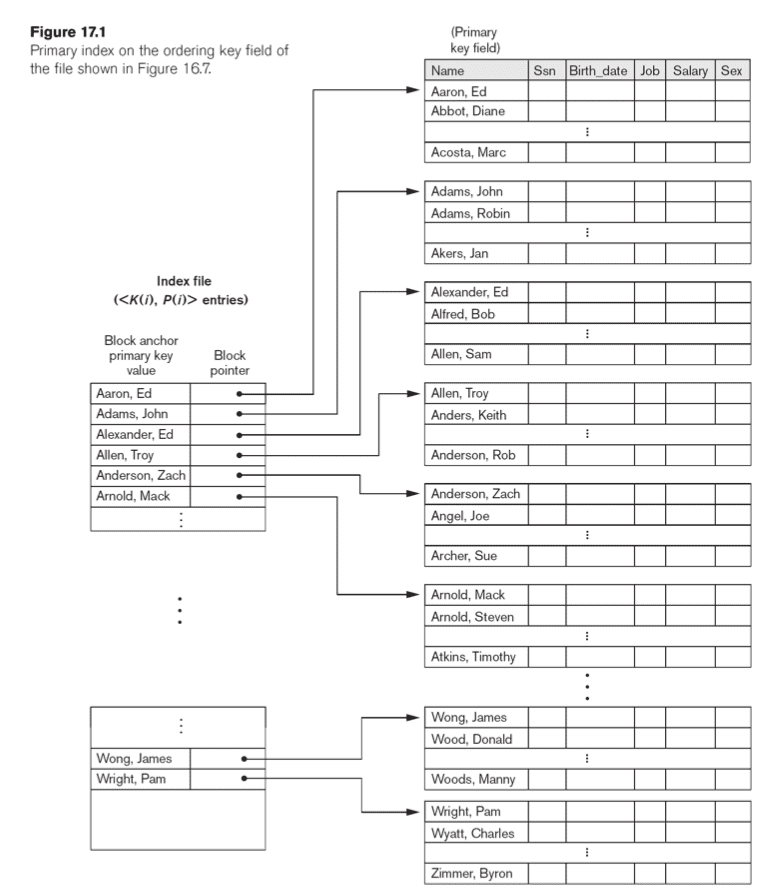
Aims
- Generate a smaller file, by having an index of an index.
Primary Index
Can be dense or sparse. A sparse index has only a selection of tuples with which you can find the other tuples.
-
Single-level Ordered Indexes
- Primary Indexes
- Clustering Indexes
- Secondary Indexes
-
Multilevel Indexes
-
Dynamic Multilevel Indexes
- B-Trees, B+-Trees
-
Indexes on Multiple Keys
To allow insertions you need to leave empty space in buckets. However, less entries in each block means you have more IO operations.
Another alternative is overflow. If a block is full, have a chain to a secondary block instead of shifting all data along blocks. Overnight you can run through the data and rebuild an index.
Or you can keep an insertion table (in memory). Don’t insert tuples into the index immediately. Once in a while you can bulk insert the tuples into the index and rebuild the index.
Most the time you don’t want to reorganise the index. If you delete “Bob Alfred”, mark it as deleted instead of removing from the index.
Clustering Index
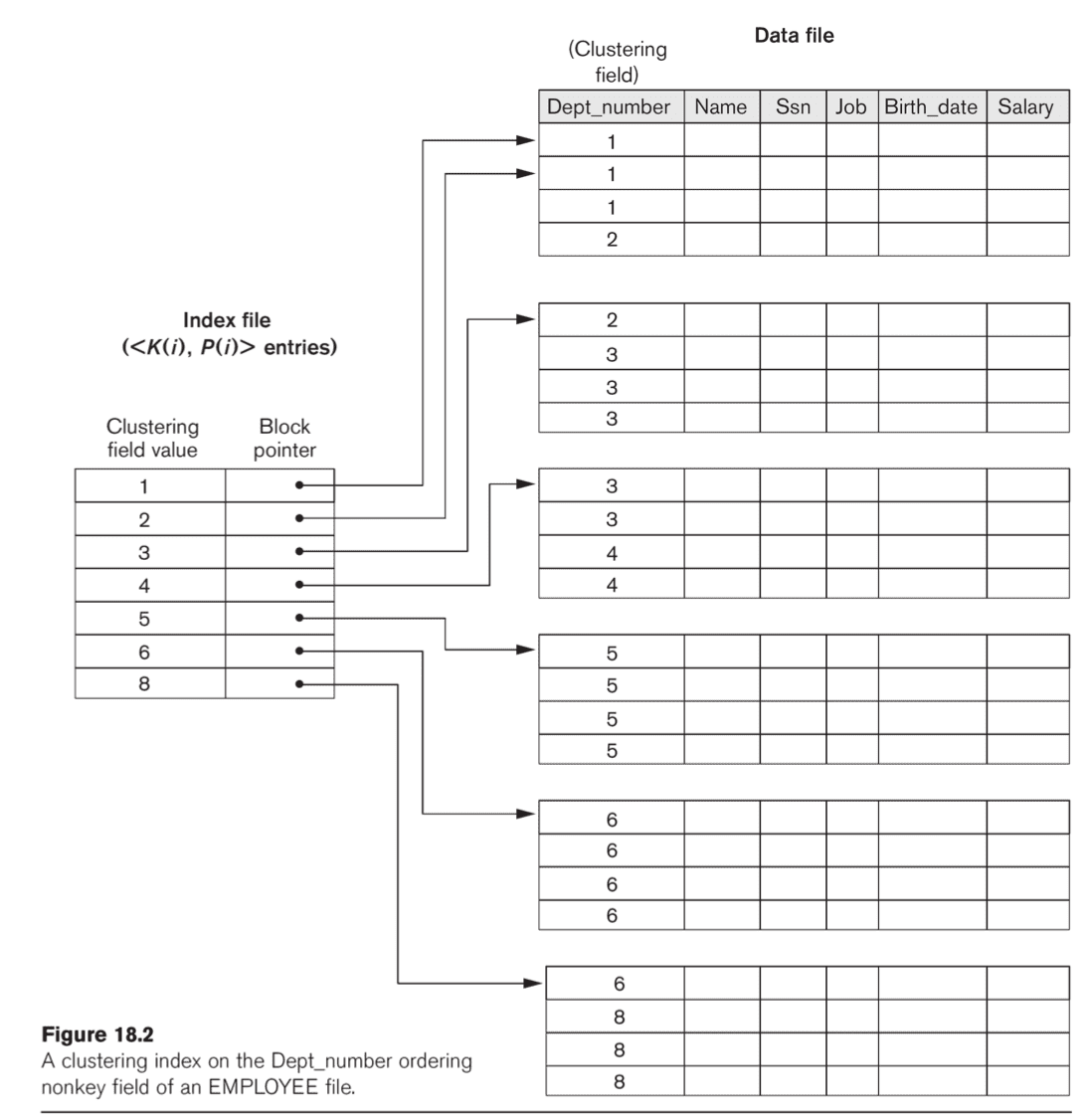
- Insertion is a challenger in the previous version.
- Cluster index where each distinct value is allocated a whole disk block
- Linked list if more than one block is needed
- Easier to update file with inserts/deletes
Secondary indexes
- Secondary indexes provide a secondary means of access to data
These are dense indexes with references to blocks. Not good for insertions, deletions. But extremely good for existence queries (0 IO operations to figure out if is in your table.)
Indexes on non-key columns
- Keep multiple entries for the same value in the index
- One entry per value, points to block of pointers that point to all the rows with that value.
Two-level index / Multi-level indexing
Bottom-up perspective: we have a big file, we want to search the file. So we need an index that’s sorted, and we want to navigate that index quickly. So we build an index of the index, and we end up with a tree.
Lecture 5 – October 13th, 2017
Missed…
Lecture 6 – October 13th, 2017
Made no notes…
Lecture 7 – October 19th, 2017
Bulk insertion
Insertion order is important in B+ trees. What if the data to be inserted is sorted? What will the tree look like at the end? When you insert your data in order you end up with a B+ tree that is very empty (minimally empty in fact).
This can be resolved by calling a sorted_bulk_insert() function instead
of a regular insert() for each tuple.
For bulk insertion, when you split, don’t split the bucket in half. Instead only bring the greatest element to the new bucket and leave the old bucket full. This is referred to as bulk loading.
Level: 3
Max-capacity: 11
Best case:
- pointers for root
- pointers for nodes in second level
- keys for leaf nodes
Worst case:
- pointers for root
- pointers for nodes in second level
- keys for leaf nodes
Data Storage
Tuning tweaking the performance of a query.
Make sure disk speeds are all the same, or be considerate of slower disks.
Handle disk addition and disk removal without turning off the
Policy constraints
- Duplicate the data in countries that are allowed (w.r.t. data privacy).
Replace cross-data centers
- Always have three different copies of data in separate locations of data centre.
The ideal parallelism for a single query is
- Minimal number of parallel scanning servers needed to satisfy the client.
Concurrent queries
- Maximizing parallelism for all of them can cause disk contention, reducing everybody’s performance.
The goal in data centres is: reach maximal parallelism while minimizing concurrency issues.
Tuning
Tuning tweaking the performance of a query.
Retrieval queries:
- Which files are accessed by the query?
- Which attributes is selection applied to?
- Is the selection equality, inequality or range?
- Which attributes are subjects of join conditions?
- Which attributes are retrieved by the query?
Update transactions:
- The files that will be updated
- The type of operation on each file (insert, modify, delete)
- The attributes for selection of a record to delete/modify
- The attributes whose values will be changed by a modify
Third one is most important. Need to build an index on attributes from 3, need to avoid index on attributes from 4, since they change often.
Building an index makes sense in most cases, but you shouldn’t have them for some attributes. For example, for attributes that are modified often.
Attributes with uniqueness (key) constraints should have an index.
CREATE [ UNIQUE ] INDEX <index name> ON <table name> (<column name> [ <order> ] )
Lecture 8 – October 23rd, 2017
External Merge Sort
-
For each block that fits in memory:
- Read into disk as much as fits in memory.
- Sort it in memory.
- Write it back.
-
Read portions of each sorted block into memory and merge them.
External merge sort:
122225-234445-11235122225-234445-11235122225-234445-11235122225-234445-11235122225-234445-11235122225-234445-11235
Sort-merge algorithm
-
Parameters of the sorting procedure:
- : number of blocks in the file to be sorted
- : available buffer space measured in blocks
- : number of runs (chunks) of the file produced
-
Small example: , , need 205 runs of 5 blocks
-
After first pass, have sorted pieces of blocks: merge them together.
- In-memory mergesort: merge two at a time (two-way merge)
- External sorting: merge as many as possible
- Limiting factor: smaller of and
Complicated SELECT operation
Selecting on many indices simultaneously (where the indices are queries
together with AND or OR).
Get the pointers to the different blocks from the secondary indexes of all of the queries indices, then… intersect the pointers, then access the blocks.
Selectivity estimation
Knowing the size of the result of a query without having to carry out the query.
Lecture 9 – October 26th, 2017
Hands-on projects
-
Data Warehousing: SQL, OLAP, from RDBMS to DWs
- In a data warehouse we have a purpose (e.g. money or sales).
- You will take this normalised DB and will make it a fact-based or subject-based table. You will drop some data. You will have a fact table with information about sales, which may refer to secondary tables with products, customers, or suppliers.
- Instructions given step by step: drop these tables, do this, do that…
- You can use MySQL, PostgreSQL, Oracle, but the queries are done for MS SQL Server.
- OLAP: for example, “give me the no. of products sold in the second half of this year in region A that weren’t sold in the first half of this year in region B.”
- Challenge: data will be missing, e.g. holidays, but they will be queried.
-
Hadoop MapReduce: Big Data hacking, text analytics
- You will be given a very big data set (and small one for testing). It will consist of updates to wiki pages.
- Since it’s big, you can’t use basic C code (or maybe you can).
- Process this data to answer questions, e.g: “who was the most active user on wikipedia”? Were they genuine edits or spam? Give the top .
- Or: “what are the articles with the highest number of revisions?”
- Biggest challenge: install Hadoop. Get it running. There is a step-by- step instruction paper on how to install it.
- Note: using Hadoop on your own machine allows you to gauge the performance better, since you have complete control over your threads (i.e. fewer context switches).
-
Column oriented data stores: Column stores for analytics, bitmaps, algorithms
- We care about aggregates (sums, avgs, analysis).
- Project is about storing columns in efficient way.
- Given any DB, how can I store data column-wise?
- Compression: most-famous one, round-length encoding.
[6, 6, 6, 6, 6, 6, 6]is turned into6 x 7, though that only works if the column is compressed. - It is assumed that the data is compressable. But that may not be the case.
- In this project: sort data on one column so that there are sequences of repetitions in the data.
- I will give you data, you will take the data and compress it, and I will give you the compression codes.
- Don’t spend too much time on details, spend time on creative solutions.
- Complex compression algorithm slow querying. You must compress it such that querying is efficient.
- Problem: multiple columns, need to sort it in multidimensional way.
- Provided with 5 data sets, one with 2 million tuples.
Objectives
- To get hands-on experience in one of the areas.
- To do something timely, and that you find interesting and stimulating.
- To let you pick something that reflects your interests.
Submission Details
-
Submission is via Tabula
- Upload a PDF of the report
- Upload a zip of the source code
-
Due Monday 4th of December (12 noon)
- Usual late scheme applies: loss of 5% of marks per working day late.
- Do make use of books/articles/websites, but cite them properly.
- Don’t copy code.
Report Format
-
Report:
- Max 5 pages (at most 3500 words) for the main part of the report
- Appendix: for detailed query outputs if required by the project description.
-
The main part:
- At least 10pt font, “sensible margins” (2cm on all sides)
- Some marks go to presentation.
- Ability to communicate is vital in whatever you go on to do
- Use graphs and diagrams where applicable.
Suggested Outline
- Introduction
-
Description of what you did
- Describe the algorithms and implementations
- Enough detail to allow someone else to repeat the process
- Include what measures you will measure the methods on
-
Results
- Experimental evaluation
- “As the data size increases, I have a linear increase in cost, …”
- For the column compressions project: “as the number of attributes increases these methods start to perform worse, but as the number of rows increases these methods become more stable.”
-
Conclusions/references
- Include proper references to work you made use of
- What more could you have done if you had more time?
Evaluation Criteria
- Quality of solutions and their evaluations [5%]
- Quality of presentation [5%]
- Quality of code, documentation, and instruction [4%]
- Description of the work done and objectives [2%]
- Framing material, references [2%]
- Results and discussion/interpretation [4%]
Report more important than the project. Keep that in mind.
Lecture 10 – October 27th, 2017
Implementing JOIN
-
Sort-merge join:
- If and are physically sorted (ordered) by value of the join attributes and , respectively, sort-merge join is very efficient.
- Both files are scanned in order of the join attributes, matching the records that have the same values for and .
-
Hash join:
- The records of and are both hashed with the same hash function on the join attributes of and of as hash keys.
- Hash join is very efficient if one of the sets fits into memory. Otherwise, bring as much as you can into memory, hash them, write back. Then read in the hashed data and join them.
- Cost if files don’t fit into memory: 3 times as many IOs.
- Assumed: your hash function behaves nicely, splits data in uniform buckets.
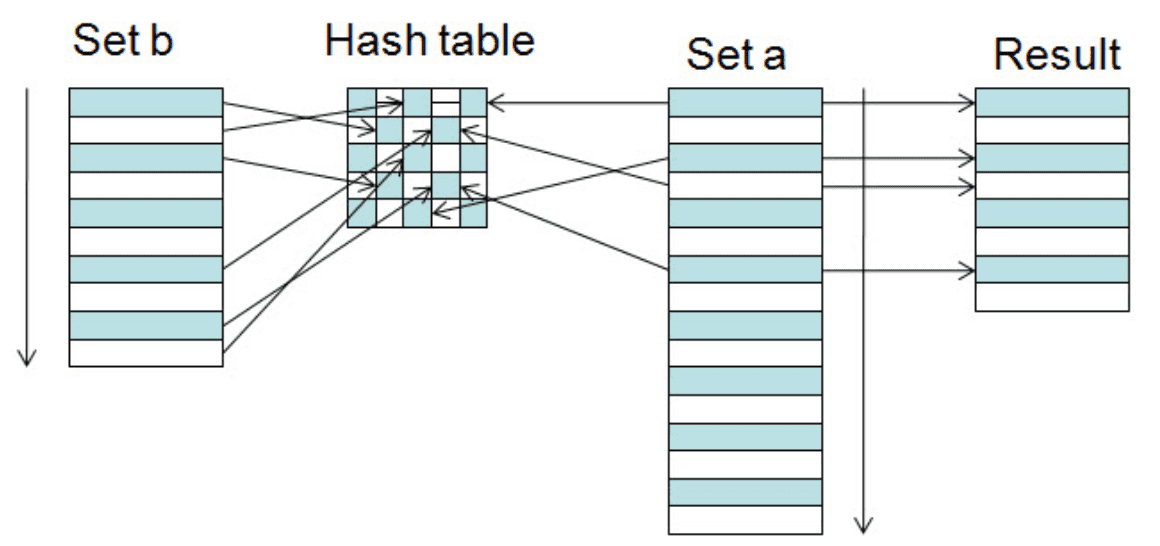
JOIN performance
-
Nested-loop join can be very expensive
-
Joining EMPLOYEE and DEPARTMENT, with EMPLOYEE for the outer loop:
EMPLOYEE read once, DEPARTMENT read times.- Read EMPLOYEE once: blocks
- Read DEPARTMENT times:
- In our examples: block reads.
-
Joining EMPLOYEE and DEPARTMENT, with DEPARTMENT for the outer loop:
EMPLOYEE read once, DEPARTMENT read times.- Read DEPARTMENT once: blocks
- Read EMPLOYEE times:
- In our examples: block reads.
JOIN selection factor
Sort-merge JOIN efficiency
Partition hash JOIN
PROJECT operation
SET operation
- Other operations: UNION, INTERSECTION, SET DIFFERENCE. These are easy. Sort the data, run the operation.
Aggregate operation
- Aggregates: MIN, MAX, COUNT, AVERAGE, SUM. Keep track of these values and update the aggregates on insertion and updates.
GROUP BY
SELECT Dno, AVG(Salary) FROM EMPLOYEE GROUP BY Dno
Apply the aggregate separately to each group of tuples
Avoid hitting the disk: pipelining
-
It is convenient to think of each operation in isolation.
- Read input from disk, write results to disk.
-
However, this is very slow: very disk intensive.
-
Use pipelining: pass results of one operator directly to the next, like unix pipes
FIRST QUERY | SECOND QUERY
Example
SELECT B,D FROM R,S WHERE R.A = "c" AND S.E = 2 AND R.C = S.C
How do we execute query?
Plan I: Cartesian product, then selection (may be a large cartesian product)
Plan II: Take first table, do a selection, take second table, do a selection, then join.
Transformation rules for relational algebra
-
Cascade of . Conjunction of selections can be broken up:
-
The operation is commutative (follows from previous)
-
Cascade of . Can ignore all but the final projection:
-
Commuting with . If selection only involves attributes in the projection list, can swap pA1, A2, … , An(sc(R)) o sc(pA1, A2, … , An (R))
-
Commutativity of ⋈ (and ́): Join (cartesian product) commutes R⋈cS=S⋈c R and R ́S=S ́R
-
Commuting s with ⋈ (or ́): If all attributes in selection condition c are in only one relation (say, R) then sc( R⋈S ) o (sc(R))⋈S Ifccanbewrittenas(c1 ANDc2)wherec1 isonlyonR,andc2 is only on S, then sc( R ⋈ S ) o (sc1(R)) ⋈ (sc2(S))
-
Commuting p with ⋈ ( ́): Write projection list L={A1…An,B1… Bn} where A’s are attributes of R, B’s are attributes of S. If join condition c involves only attributes in L, then: pL(R ⋈c S) o ( pA1,…An(R)) ⋈c (pB1,…Bn(S)) Can also allow join on attributes not in L with an extra projection 82 CS346 Advanced Databases Transformation rules for relational algebra
-
Commutativity of set operators Operations È and Ç are commutative ( / is not)
-
Associativity of ⋈, ́, È, Ç These operations are individually associative: (R q S) q T = R q (S q T) where q is the same op throughout
-
Commuting s with set operations scommuteswithÈ,Çand/:sc (rqS)o(sc(R))q(sc(S))
-
The p operation commutes with È: pL(R È S) o (pL(R)) È (pL(S))
-
Converting a (s, ́) sequence into a ⋈ If the condition c of selection s following a ́ corresponds to a join condition, then: (sc(R ́ S)) o (R ⋈c S)
Lecture 11 – October 30th, 2017
Example cost estimates for SELECT
Conjunctive selection: run the most selective query, then check the others.
Query optimizer finds possible strategies, estimates cost of each.
Usually you pick using an index over sequential scan. But if you’re doing a range query, even a selective one, on a secondary index, you might end up being slower than a linear scan. This would be due to the random IOs that you end up doing when using the secondary index.
Running hints in SQL: I know that this is a very rare value, so definitely use the index and don’t estimate the query.
-
To estimate cost of
JOIN, need to know how many tupled result.- Store as a selectivity ratio: size of join to size of cartesian product.
Lecture n – November 13th, 2017
Using MapReduce as a relational database
-
Selection
- Mapper checks if the condition is met.
-
Projection
- Mapper maps the tuples to a tuple with just the columns you want.
-
Group-by
-
Mapper maps tuples to key-value pairs. Reducer combines key-value pairs with the same keys into a list.
-
Example, you have
(url, time)tuples, what’s the average load time for each url? -
In SQL:
SELECT url, AVG(time) FROM visits GROUP BY url -
In MapReduce:
- Map over tuples, emit time, keyed by url
- MapReduce automatically groups by keys
- Compute average in reducer
- Optimize with combiners
- Not possible to put averages directly, so put
(sum, N)tuples.
-
-
Reduce-side Join
- Mapper maps both tables to key-value pairs with the key being the join attribute.
- Reducer combines the key-valued pairs into the result.
- Everything is done for us in the shuffle phase.
-
Map-side Join
- If the tables are sorted and partitioned by the join key.
- Then you can line the two tables up and do the join in parallel.
-
In-memory Join
- Run a hash on the small file and place it in the memory of every node. Alternatively, you can get each node to hash the small file.
- In the map phase each node will map their tuples onto their hash table of the small files.
Summary
- MapReduce can be used to carry out selection, projection, group-bys, and joins.
-
Multiple strategies for relational joins
- Prefer in-memory over map-side over reduce-side.
- Reduce-side is most general, in-memory is most optimal.
HBase
HBase (Hadoop Database) is a distributed database that makes small queries fast. It’s much faster than traditional Hadoop operations.
-
Suitable for sparse data, with a lot of attributes that are often null.
-
The HBase data model is similar to the relational model:
- Data is stored in tables, which have rows
- Each row is identifier/referenced by a unique key value
- Rows have columns, grouped into column families.
-
Data (bytes) is stored in cells
- Each cell is identified by (row, column-family, column)
- Limited support for secondary indexes on non-key values
- Cell contents are versioned.
-
Data is stored in Hfiles, usually under HDFS.
- Empty cells are not explicitly stored – allows for very sparse data.
Lecture n – November 20th, 2017
Database Transactions:
A set of operations that must be carried out together. Nothing else can happen in the mean time.
Transaction processing:
Transaction (T1)
read_item(X);
X := X - N;
write_item(X);
read_item(Y);
Y := Y + N;
write_item(Y);Transaction (T2)
read_item(X);
X := X + M;
write_item(X);(T1) r(X); w(X); r(Y); w(Y); c
(T2) r(X); w(X); c
Solution 1
- Serial execution of T1 and T2:
. - This is slow, but always correct.
Solution 2
- Interleaved execution of T1 and T2:
. - This may not be correct.
The transaction processor takes many transactions and interleaves them properly.
- Atomicity: a transaction either commits or aborts. All steps are carried out or none of them are.
- Consistency: transactions should preserve database consistency.
- Isolation: every transaction is carried out as if its carried out in isolation.
- Durability: aborting a transaction will not lead to committed changes being lost.
How to enforce atomicity and durability: if a transaction fails after some operation, it must be undone. Roll-back the earlier operations using systems log. All changes are written to logs.
Things in a log:
[start_transaction, T]T is a unique transaction id.[write_item, T, X, old_value, new_value]Transaction T affects item X.[read_item, T, X]Transaction T reads item X.[commit, T]Transaction has been completed.[abort, T]Transaction has been aborted.
Commit points mark successful completion of transactions. If a system failure occurs, find all transactions T that have started but have not been committed. Roll back their associated operations to undo their effect.
To enforce durability: transactions can only commit after the commit of every transaction from which they read. This can cause cascading aborts. This can be avoided by enforcing the rule: read only committed data.
To produce a valid interleaved schedule, the scheduler has to build a schedule that is equivalent to any serial schedule of transactions. It places the conflicting operations in the same order, and does not reorder them. For non-conflicting operations we don’t care.
If there is a cycle in the dependency graph of transactions, then there is not serialisable execution possible.